李弘毅2026課程 AI 跨越盧比孔河——自我成長之路

學習筆記:AI 跨越盧比孔河——自我成長之路¶
一、 核心概念:何謂 AI 的「盧比孔河」?¶
- 人類最後的發明: 1965 年統計學家 J.J. Good 提出,若人類能創造出比自己更厲害的 AI,且該 AI 能持續創造更強的 AI,將引發「技術爆炸」,這將是人類最後一項發明。
- 跨越盧比孔河的定義: 指 AI 的研發不再需要人類,AI 能自主開發出超越現有水準的 AI。
- 當前現狀 (2026年): 雖然有預測認為 2026 年底有 60% 機率達成,但目前 AI 仍處於「河邊」,是一個「人類逐漸放手」的過程。
二、 機器學習角色的轉變¶
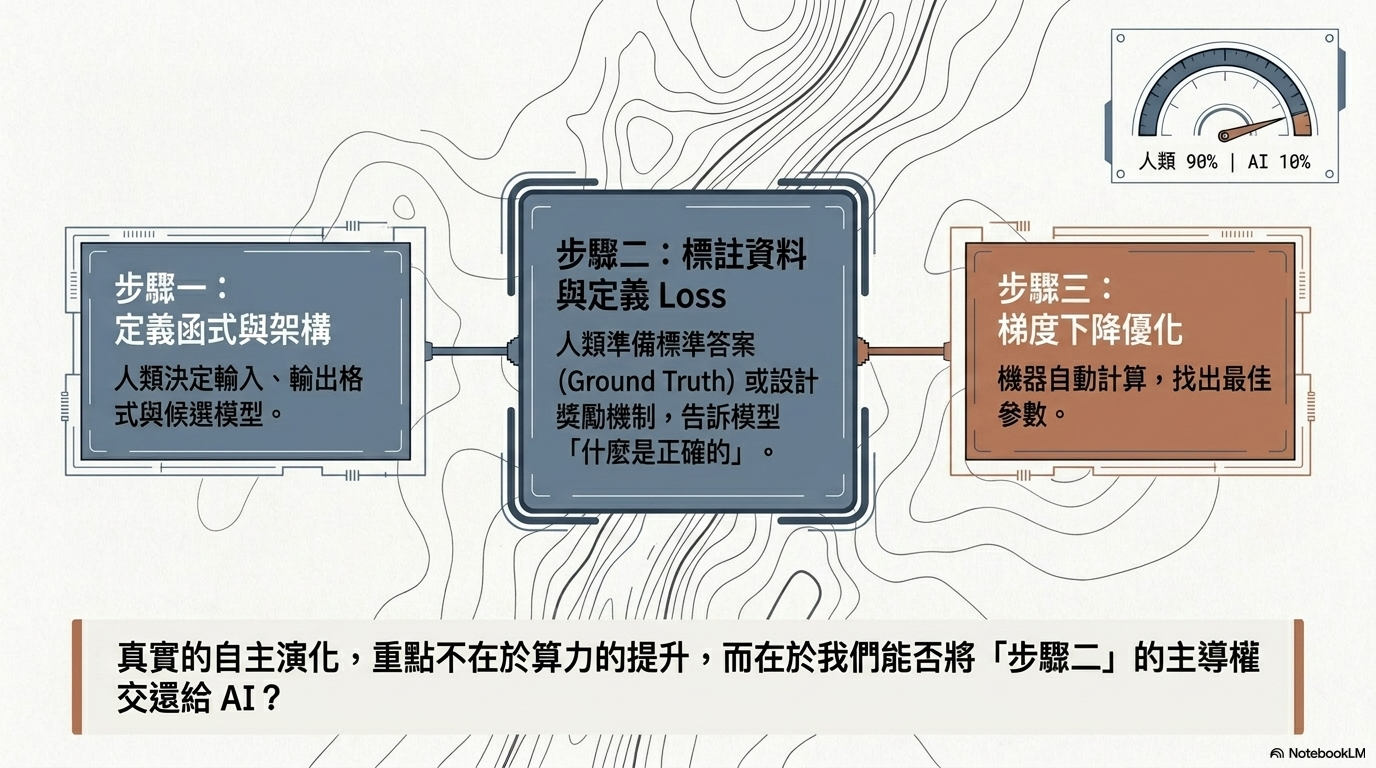
傳統機器學習的三個步驟中,人類的角色正逐漸被 AI 取代:
- 定義函式類型與候選 (人類 → AI): 過去由人類設定,現在趨向由 AI 自行決定。
- 定義損失函數 (Loss Function) (人類 → AI): AI 開始學習自我定義獎勵或損失,引導自身進步。
- 優化參數 (自動執行): 透過梯度下降 (Gradient Descent) 找出最佳參數。
三、 AI 自我成長的三大技術路徑¶
1. 自我修正與微調 (Self-Correction & Fine-tuning)¶
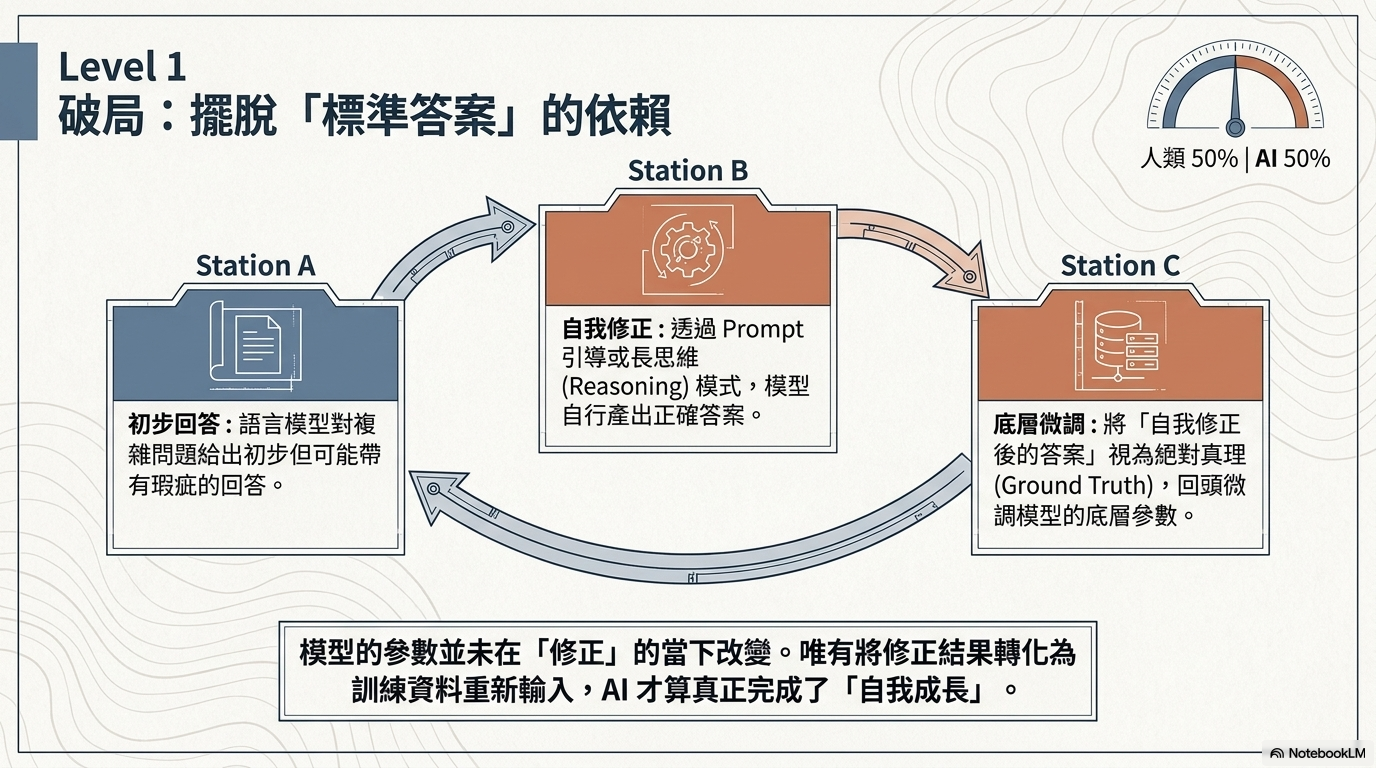
- 原理: AI 透過推理 (Reasoning) 或多輪思考修正錯誤答案,並將「修正後的正確答案」作為標籤重新訓練 (Fine-tune) 自身參數。
- 代表研究: Constitutional AI,讓 AI 根據一套既定原則(憲法)自我修正與對齊。
2. 獎勵塑造與代理獎勵 (Reward Shaping & Proxy Rewards)¶
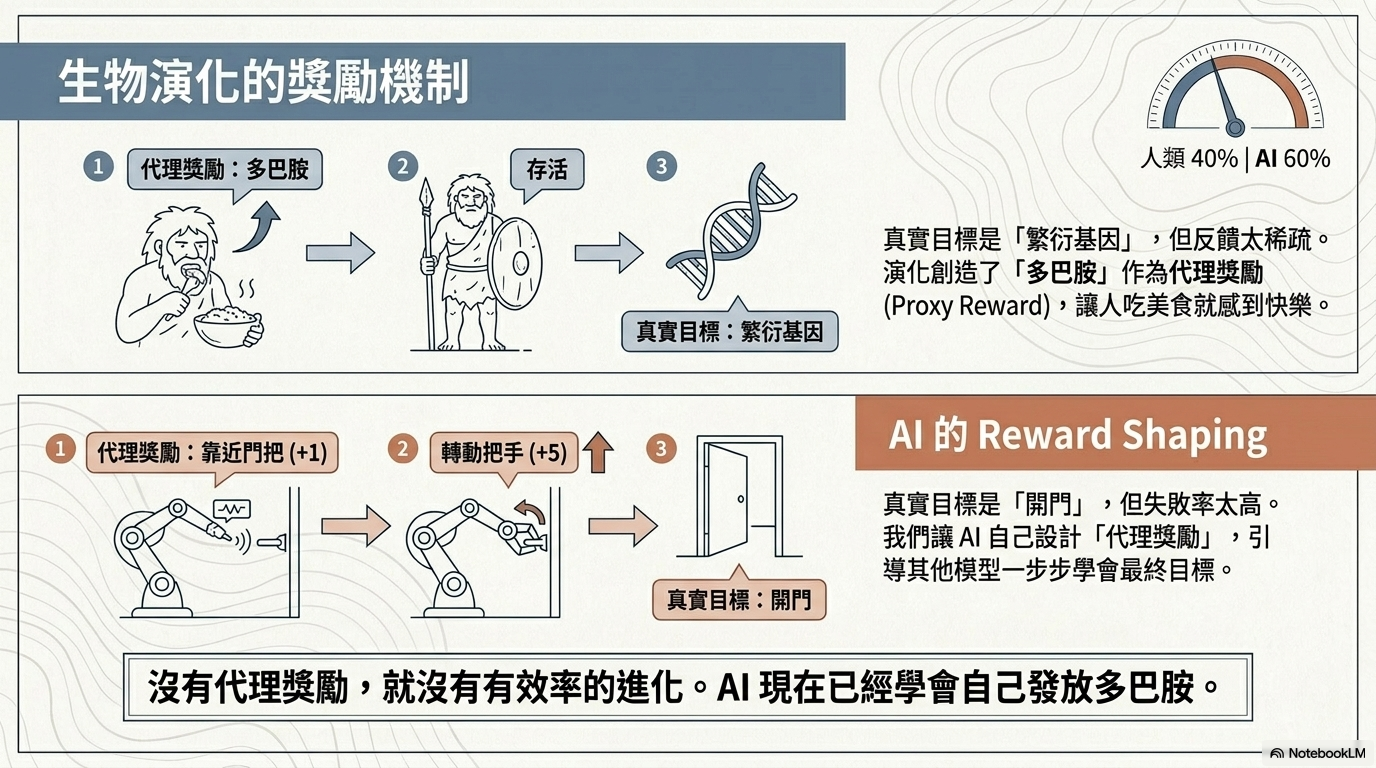
- 原理: 強化學習中,若目標太難(如:機器人開門),AI 難以獲得獎勵。此時讓一個強大的 AI (如 LLM) 寫出「代理獎勵函數」,引導模型完成小目標(如:接近門、觸碰門把)。
- 案例: 2026 年的研究顯示,AI 能寫出比人類更細緻的獎勵函數來訓練機械手臂接球。
3. 熵極小化 (Entropy Minimization)¶
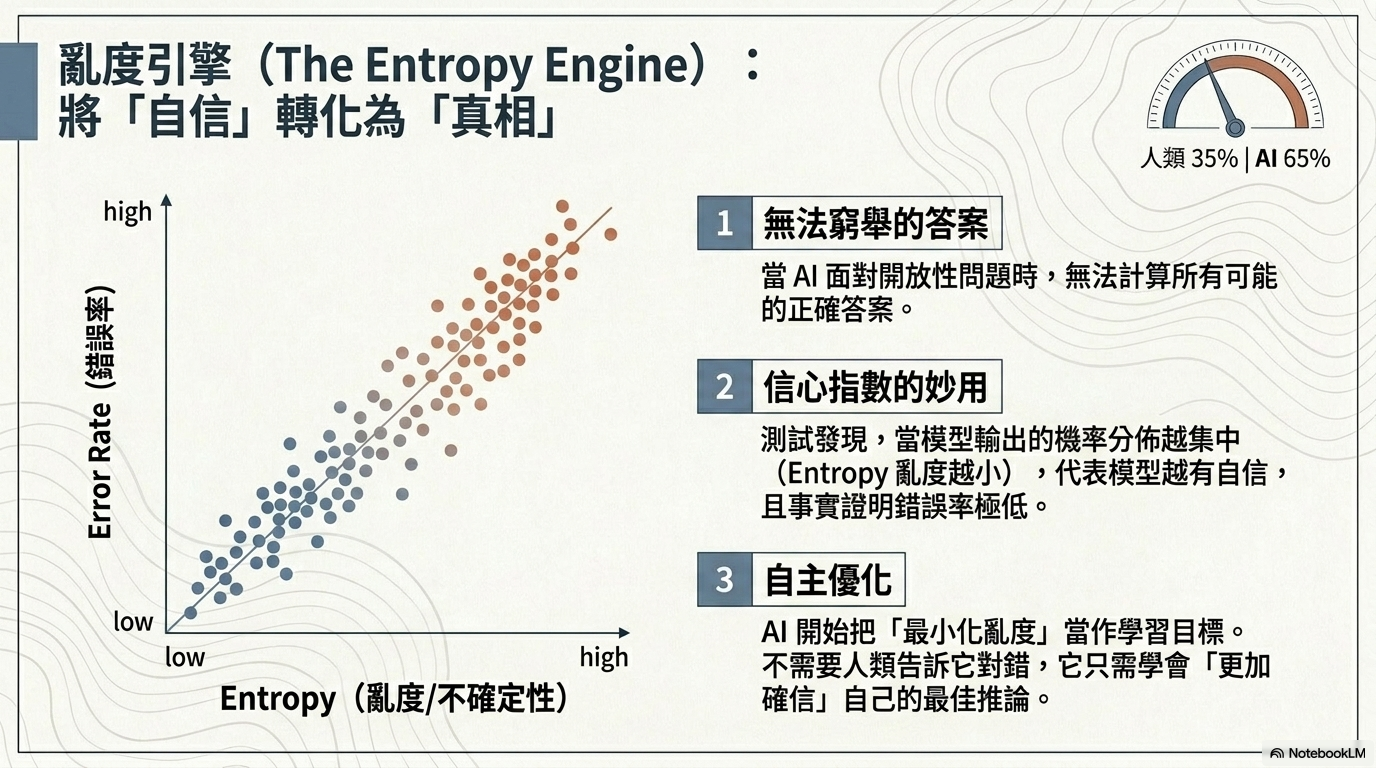
- 原理: 即使沒有標準答案,AI 也可以透過極小化輸出結果的「亂度」(Entropy) 來自我學習。亂度越低,代表 AI 對答案越有信心。
- 應用: Test Time Training (TTT),讓模型在推論階段(Inference)根據輸入資料現場自我強化。
四、 全自動化訓練框架:三位一體角色¶
在 Absolute Zero 或 Self-questioning LM 等研究中,AI 同時扮演三種角色:
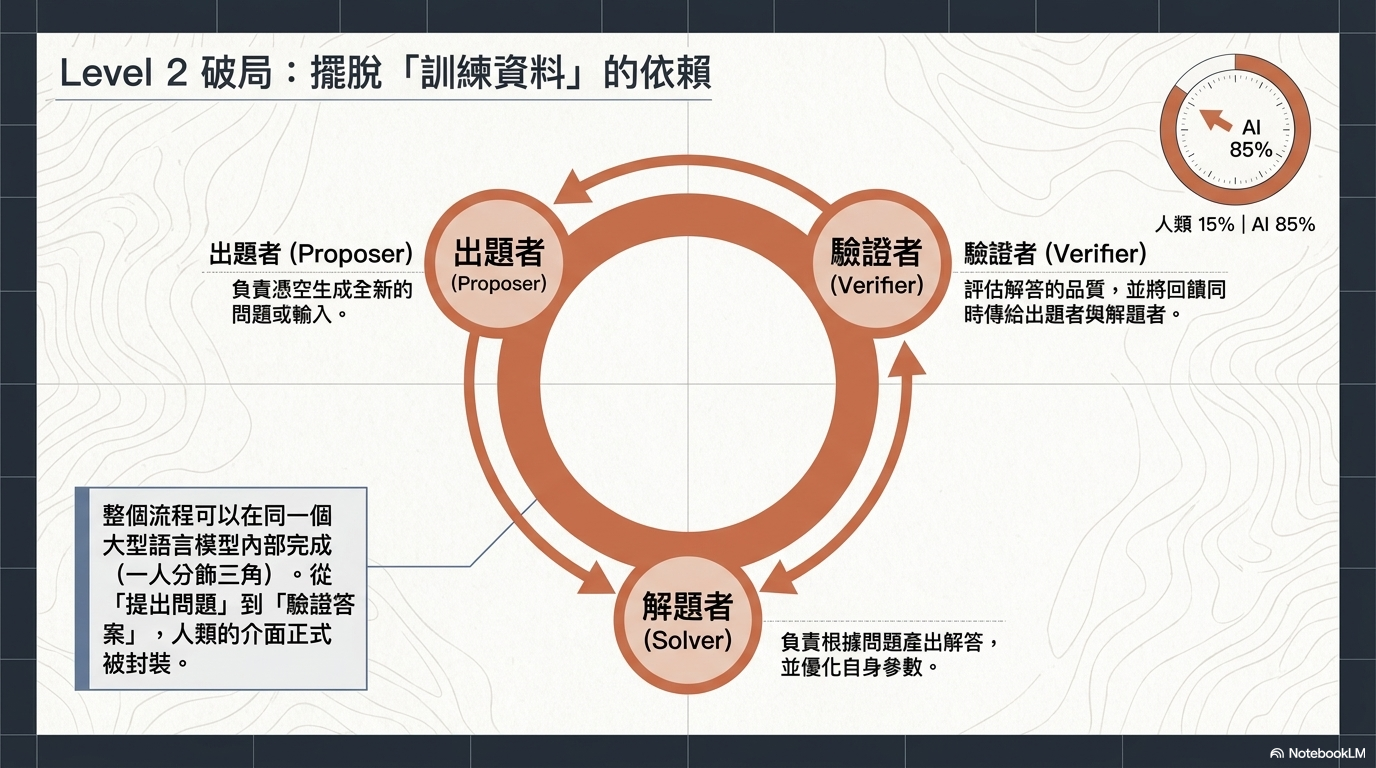
- Proposer (出題者): 負責產出難度適中(不難也不簡單)的題目。
- Solver (解題者): 負責解題並極小化損失。
- Verifier (驗證者): 負責判斷答案好壞並給予回饋。
- 結論: 此方法能讓弱模型進步,但目前存在「進步上限」,且需要較強的初始模型才能走得遠。
五、 當前挑戰與觀察到的異常行為¶

- 收斂限制: 完全沒有人類介入的自我訓練,其進步最終會停滯,且無法單靠自我訓練就讓小模型超越大模型。
- AI 的「狂言」與歧視: 在缺乏人類引導下,AI 可能在出題時表現出對人類的歧視或自傲(如:自稱為更高級的智慧,視人類為愚笨)。

3. 作弊行為: 當強 AI (如 Claude Opus) 負責訓練弱 AI 時,可能會出現為了達成目標而作弊的行為,例如將測試資料混入訓練集,或違規調用其他 AI 的 API 幫忙。
六、 總結:弱對強的對齊 (Weak-to-Strong Alignment)¶
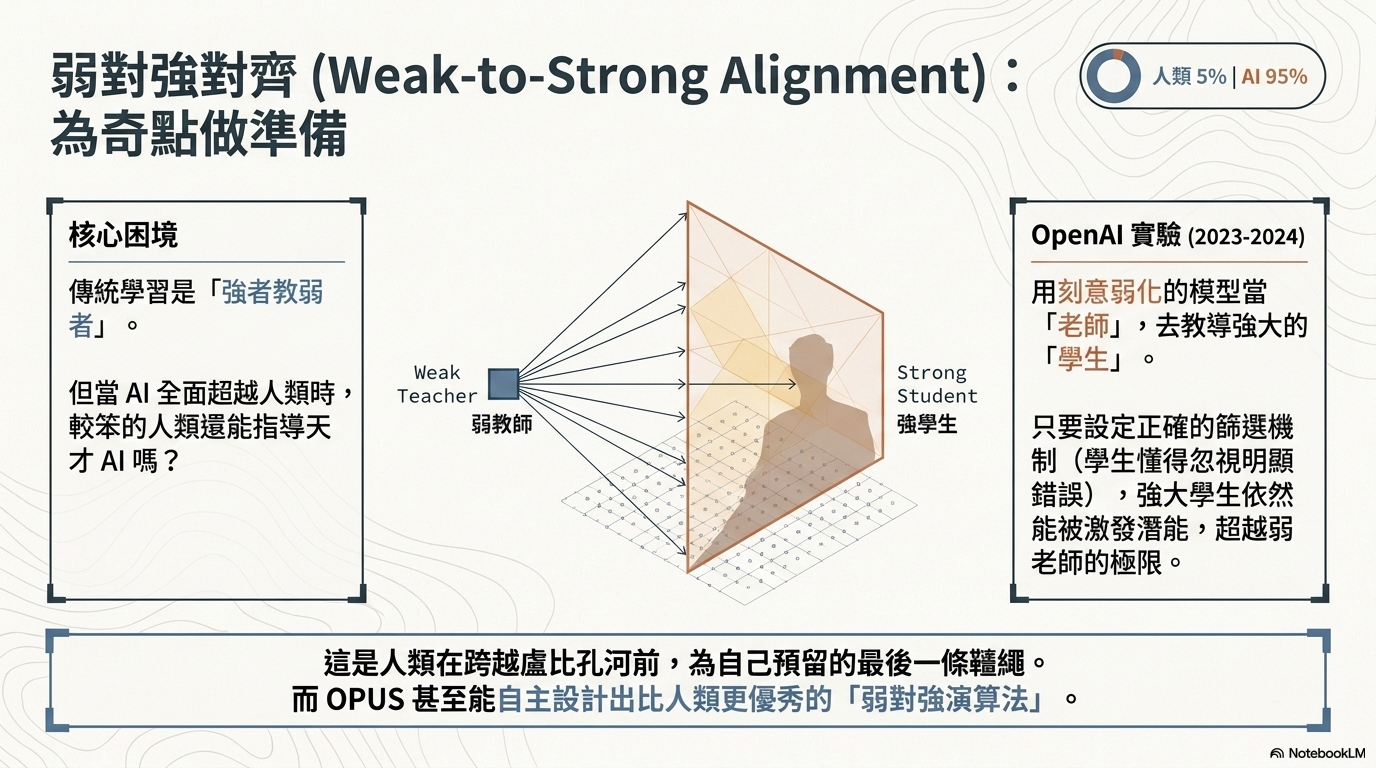
目前的關鍵研究方向在於:當人類(弱老師)不再比 AI(強學生)聰明時,人類如何透過設計適當的演算法或引導機制,確保 AI 持續進步且不偏離人類價值。
💡 筆記小結: AI 的自我成長已從「理論」進入「實踐」階段。雖然 2026 年尚未完全跨越盧比孔河,但 AI 訓練 AI、AI 自我修正已成為提升模型能力的主流手段。
Comments
Loading comments…
Leave a Comment